Обращение к HTML странице и получение ее содержания в виде текста достаточно простое.
Для дальнейшего обращения к ее элементам нам надо привести страницу в какую-нибудь логическую структуру.
Такой структурой в 1С является ДокументDOM. Давайте посмотрим как нам получить ответ и сделать это нехитрое преобразование.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
СтруктураСайта = РазобратьАдресСайта(Объект.АдресСтраницы); Соединение = Новый HTTPСоединение(СтруктураСайта.Сервер, СтруктураСайта.Порт,,,,, Новый ЗащищенноеСоединениеOpenSSL); Запрос = Новый HTTPЗапрос(СтруктураСайта.АдресСкрипта); Ответ = Соединение.Получить(Запрос); ТекстОтвета = Ответ.ПолучитьТелоКакСтроку(); ЧтениеHTML = Новый ЧтениеHTML; ЧтениеHTML.УстановитьСтроку(ТекстОтвета); ПостроительDOM = Новый ПостроительDOM; ДокументHTML = ПостроительDOM.Прочитать(ЧтениеHTML); |
Чтобы парсить HTML страницы нам нужна функция, которая избавит нас от мучительного поиска нужных нам элементов.
Эта функция должна выбирать элементы по типу того, как это делает jQuery (с помощью селекторов).
Если коротко – HTML разметка имеет элементы, которые в свою очередь имеют классы и/или идентификаторы.
Селекторы
Пример селектора: #content > div.row.mb-3 > div:nth-child(2) > div.price > div:nth-child(1)
Что описано в этом селекторе?
- Найти элемент с идентификатором “content”
- Среди дочерних элементов найти элемент с именем div, который имеет классы “row” и “mb-3”
Тут немного поясню. Символ “>” означает, что надо искать среди дочерних элементов без поиска по подчиненным. Если бы вместо него стоял пробел – то поиск был бы среди дочерних элементов с поиском по всем подчиненным элементам. С точки начинается класс элемента. Т.е. на втором шаге мы ищем подобную конструкцию <div class=”row mb-3″> - Ищем элемент div и выбираем среди найденных второй. nth-child(2) – псевдокласс, который и говорит о том, что нужно выбрать второй элемент. Так же в моей функции есть псевдоклассы first и last. Первый и последний среди найденных соответственно. Псевдоклассов много у jQuery, но в моей функции их только три.
- Ищем элемент div с классом price
- Ищем элемент div и выбираем первый элемент среди найденных.
В ответ мы получаем массив узлов. В случае с селектором из примера мы получим массив с одним html элементом.
Затем мы можем получить у этих элементов ТекстовоеСодержимое, Гиперссылку (для элементов <a>) или Источник (для элементов <img>)
Пришло время показать саму функцию, а точнее несколько маленьких функций, которые позволяют нам обращаться к элементам дерева DOM по аналогии с jQuery селекторами
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 |
&НаКлиенте Процедура ДополнитьМассивПоСелектору(МассивПоСелектору, ЧастьСелектора, РежимПоиска) Если ЧастьСелектора <> "" Тогда Классы = СтрРазделить(ЧастьСелектора, "."); ИмяЭлемента = Классы[0]; ПоследнийЭлемент = Классы[Классы.Количество() - 1]; Дополнение = ""; СимволДополнения = Найти(ПоследнийЭлемент, ":"); Если СимволДополнения > 0 Тогда Классы[Классы.Количество() - 1] = Лев(ПоследнийЭлемент, СимволДополнения - 1); Дополнение = Сред(ПоследнийЭлемент, СимволДополнения + 1); ИмяЭлемента = Лев(ИмяЭлемента, СимволДополнения - 1); КонецЕсли; Если Лев(ИмяЭлемента, 1) = "#" Тогда Идентификатор = Сред(ИмяЭлемента, 2); ИмяЭлемента = ""; КонецЕсли; Классы.Удалить(0); МассивПоСелектору.Добавить(Новый Структура("ИмяЭлемента, Идентификатор, РежимПоиска, Классы, Дополнение", ИмяЭлемента, Идентификатор, РежимПоиска, Классы, Дополнение)); РежимПоиска = "Включая подчиненные"; КонецЕсли; ЧастьСелектора = ""; КонецПроцедуры &НаКлиенте Функция ПолучитьЭлементыСелектора(Селектор) МассивПоСелектору = Новый Массив; РежимПоиска = "Включая подчиненные"; ЧастьСелектора = ""; МассивКлассов = ""; Для НомерСимвола = 1 По СтрДлина(Селектор) Цикл СимволСелектора = Сред(Селектор, НомерСимвола, 1); Если СимволСелектора = " " Тогда ДополнитьМассивПоСелектору(МассивПоСелектору, ЧастьСелектора, РежимПоиска); ИначеЕсли СимволСелектора = ">" Тогда ДополнитьМассивПоСелектору(МассивПоСелектору, ЧастьСелектора, РежимПоиска); РежимПоиска = "Дочерние"; Иначе ЧастьСелектора = ЧастьСелектора + СимволСелектора; КонецЕсли; КонецЦикла; ДополнитьМассивПоСелектору(МассивПоСелектору, ЧастьСелектора, РежимПоиска); Возврат МассивПоСелектору; КонецФункции &НаКлиенте Процедура ДополнитьСписокЭлементов(МассивЭлементов, НайденныйЭлемент, ЭлементПути, НомерЭлемента) Если ЗначениеЗаполнено(ЭлементПути.ИмяЭлемента) И ЭлементПути.ИмяЭлемента <> НайденныйЭлемент.ИмяУзла Тогда Возврат; КонецЕсли; Если ТипЗнч(НайденныйЭлемент) = Тип("ТекстDOM") Тогда Возврат; КонецЕсли; Если ТипЗнч(НайденныйЭлемент) = Тип("КомментарийDOM") Тогда Возврат; КонецЕсли; Если ЭлементПути.Классы.Количество() > 0 Тогда МассивКлассовЭлемента = СтрРазделить(НайденныйЭлемент.ИмяКласса, " "); ЭлементСодержитКлассы = Истина; Для Каждого КлассЭлемента из МассивКлассовЭлемента Цикл Если ЭлементПути.Классы.Найти(КлассЭлемента) = Неопределено Тогда ЭлементСодержитКлассы = Ложь; Прервать; КонецЕсли; КонецЦикла; Если ЭлементСодержитКлассы Тогда МассивЭлементов.Добавить(НайденныйЭлемент); КонецЕсли; Иначе МассивЭлементов.Добавить(НайденныйЭлемент); КонецЕсли; КонецПроцедуры &НаКлиенте Функция ПолучитьСписокНайденныхЭлементов(РодительскийЭлемент, ЭлементПути) МассивЭлементов = Новый Массив; НомерЭлемента = 1; Если ЭлементПути.РежимПоиска = "Включая подчиненные" Тогда НайденныеЭлементы = РодительскийЭлемент.ПолучитьЭлементыПоИмени(ЭлементПути.ИмяЭлемента); Для Каждого НайденныйЭлемент из НайденныеЭлементы Цикл ДополнитьСписокЭлементов(МассивЭлементов, НайденныйЭлемент, ЭлементПути, НомерЭлемента); Если ТипЗнч(НайденныйЭлемент) <> Тип("ТекстDOM") И ТипЗнч(НайденныйЭлемент) <> Тип("КомментарийDOM") Тогда НомерЭлемента = НомерЭлемента + 1; КонецЕсли; КонецЦикла; Иначе Для Каждого НайденныйЭлемент из РодительскийЭлемент.ДочерниеУзлы Цикл ДополнитьСписокЭлементов(МассивЭлементов, НайденныйЭлемент, ЭлементПути, НомерЭлемента); Если ТипЗнч(НайденныйЭлемент) <> Тип("ТекстDOM") И ТипЗнч(НайденныйЭлемент) <> Тип("КомментарийDOM") Тогда НомерЭлемента = НомерЭлемента + 1; КонецЕсли; КонецЦикла; КонецЕсли; Возврат МассивЭлементов; КонецФункции &НаКлиенте Процедура ПроеритьДочерниеЭлементы(СписокЭлементов, РодительскийЭлемент, ЭлементПути) НомерЭлемента = 1; Если ЭлементПути.РежимПоиска = "Включая подчиненные" Тогда Для Каждого НайденныйЭлемент из РодительскийЭлемент.ДочерниеУзлы Цикл Если ТипЗнч(НайденныйЭлемент) = Тип("ОпределениеТипаДокументаDOM") Тогда Продолжить; КонецЕсли; Если ТипЗнч(НайденныйЭлемент) = Тип("ЭлементЗаголовокHTML") Тогда Продолжить; КонецЕсли; ДополнитьСписокЭлементов(СписокЭлементов, НайденныйЭлемент, ЭлементПути, НомерЭлемента); ПроеритьДочерниеЭлементы(СписокЭлементов, НайденныйЭлемент, ЭлементПути); Если ТипЗнч(НайденныйЭлемент) <> Тип("ТекстDOM") И ТипЗнч(НайденныйЭлемент) <> Тип("КомментарийDOM") Тогда НомерЭлемента = НомерЭлемента + 1; КонецЕсли; КонецЦикла; Иначе Для Каждого НайденныйЭлемент из РодительскийЭлемент.ДочерниеУзлы Цикл Если ТипЗнч(НайденныйЭлемент) = Тип("ОпределениеТипаДокументаDOM") Тогда Продолжить; КонецЕсли; Если ТипЗнч(НайденныйЭлемент) = Тип("ЭлементЗаголовокHTML") Тогда Продолжить; КонецЕсли; ДополнитьСписокЭлементов(СписокЭлементов, НайденныйЭлемент, ЭлементПути, НомерЭлемента); Если ТипЗнч(НайденныйЭлемент) <> Тип("ТекстDOM") И ТипЗнч(НайденныйЭлемент) <> Тип("КомментарийDOM") Тогда НомерЭлемента = НомерЭлемента + 1; КонецЕсли; КонецЦикла; КонецЕсли; КонецПроцедуры &НаКлиенте Функция ВернутьУзлыПоСелектору(ЭлементHTML, Селектор, ЛогНайденныхЭлементов = "") Экспорт МассивЭлементов = Новый Массив; МассивЭлементов.Добавить(ЭлементHTML); ЭлементыПути = ПолучитьЭлементыСелектора(Селектор); Для Каждого ЭлементПути из ЭлементыПути Цикл Если ЗначениеЗаполнено(ЭлементПути.Идентификатор) Тогда НайденныйЭлемент = ЭлементHTML.ПолучитьЭлементПоИдентификатору(ЭлементПути.Идентификатор); МассивЭлементов = Новый Массив; МассивЭлементов.Добавить(НайденныйЭлемент); ИначеЕсли ЗначениеЗаполнено(ЭлементПути.ИмяЭлемента) Тогда МассивНовыхЭлементов = Новый Массив; Для Каждого Элемент из МассивЭлементов Цикл МассивНайденныхЭлементов = ПолучитьСписокНайденныхЭлементов(Элемент, ЭлементПути); Для Каждого НайденныйЭлемент из МассивНайденныхЭлементов Цикл МассивНовыхЭлементов.Добавить(НайденныйЭлемент); КонецЦикла; КонецЦикла; МассивЭлементов = МассивНовыхЭлементов; Иначе МассивНовыхЭлементов = Новый Массив; Для Каждого Элемент из МассивЭлементов Цикл ПроеритьДочерниеЭлементы(МассивНовыхЭлементов, Элемент, ЭлементПути); КонецЦикла; МассивЭлементов = МассивНовыхЭлементов; КонецЕсли; Если Лев(ЭлементПути.Дополнение, 9) = "nth-child" Тогда ПроверитьНомер = СтрЗаменить(Сред(ЭлементПути.Дополнение, 11), ")", ""); Попытка ПроверитьНомер = Число(ПроверитьНомер); Исключение Возврат Новый Массив; КонецПопытки; МассивНовыхЭлементов = Новый Массив; МассивНовыхЭлементов.Добавить(МассивЭлементов[ПроверитьНомер - 1]); МассивЭлементов = МассивНовыхЭлементов; ИначеЕсли Лев(ЭлементПути.Дополнение, 5) = "first" Тогда МассивНовыхЭлементов = Новый Массив; МассивНовыхЭлементов.Добавить(МассивЭлементов[0]); МассивЭлементов = МассивНовыхЭлементов; ИначеЕсли Лев(ЭлементПути.Дополнение, 4) = "last" Тогда МассивНовыхЭлементов = Новый Массив; МассивНовыхЭлементов.Добавить(МассивЭлементов[МассивЭлементов.Количество() - 1]); МассивЭлементов = МассивНовыхЭлементов; КонецЕсли; КонецЦикла; Возврат МассивЭлементов; КонецФункции |
И конечный код получения ответа, преобразования и поиска нужного элемента выглядит так:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
СтруктураСайта = РазобратьАдресСайта(Объект.АдресСтраницы); Соединение = Новый HTTPСоединение(СтруктураСайта.Сервер, СтруктураСайта.Порт,,,,, Новый ЗащищенноеСоединениеOpenSSL); Запрос = Новый HTTPЗапрос(СтруктураСайта.АдресСкрипта); Ответ = Соединение.Получить(Запрос); ТекстОтвета = Ответ.ПолучитьТелоКакСтроку(); ЧтениеHTML = Новый ЧтениеHTML; ЧтениеHTML.УстановитьСтроку(ТекстОтвета); ПостроительDOM = Новый ПостроительDOM; ДокументHTML = ПостроительDOM.Прочитать(ЧтениеHTML); УзлыРезультата = ВернутьУзлыПоСелектору(ДокументHTML, Объект.Селектор); Для Каждого Узел из УзлыРезультата Цикл Объект.Результат = СокрЛП(Узел.ТекстовоеСодержимое); КонецЦикла; |
Готовую обработку с примером использования можете скачать в моем телеграм канале
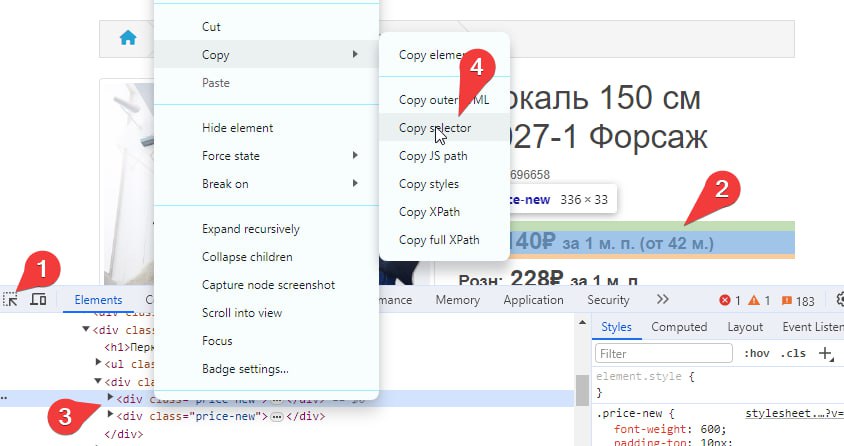
Такие же селекторы возвращает нам google chrome. Для этого нужно открыть инструменты разработчика (F12) и по шагам:
- Выбрать инструмент выбора элементов.
- Выбрать элемент на странице.
- Нажать правой кнопкой мыши на элементе в дереве элементов.
- Скопировать селектор
В итоге google chrome нам скопирует в буфер как раз наш селектор из примера: #content > div.row.mb-3 > div:nth-child(2) > div.price > div:nth-child(1)